🛡️ OpenRefine en DFIR y CSIRT: La navaja suiza para limpiar y enriquecer logs
✳ Introducción: El problema de la «Data Sucia» en Ciberseguridad
En los equipos CSIRT, SOC y en investigaciones de DFIR (Digital Forensics & Incident Response), los analistas pasan el 80% del tiempo preparando datos y solo el 20% analizándolos. Trabajamos constantemente con fuentes heterogéneas:
- Firewalls y Proxies
- Web servers (IIS, Apache, Nginx)
- Registros DNS
- Logs de VPN
- Alertas de Endpoint (EDR)
- Exportaciones masivas CSV/JSON de un SIEM
El problema universal es que los logs llegan «sucios», impidiendo una correlación eficiente. Nos encontramos con formatos de fecha dispares (MM-DD-YYYY vs DD/MM/YYYY), codificaciones rotas, usuarios duplicados por mayúsculas/minúsculas y delimitadores inconsistentes.
Para solucionar esto, muchos recurren a Excel (que se cuelga con archivos grandes y modifica datos automáticamente) o a scripts de Python (que requieren tiempo de desarrollo). Aquí es donde entra la herramienta definitiva: OpenRefine.
🧩 ¿Qué es realmente OpenRefine?
A menudo descrito como «El Photoshop para los datos», OpenRefine (anteriormente Google Refine) es una herramienta de escritorio potente, gratuita y de código abierto diseñada para trabajar con datos desordenados.
A diferencia de una hoja de cálculo tradicional, OpenRefine funciona más como una base de datos visual. No editas «celda por celda»; editas patrones.
¿Por qué OpenRefine es superior para DFIR?
Para un analista forense o de inteligencia de amenazas, OpenRefine ofrece ventajas críticas sobre Excel o comandos de terminal (sed/awk):
- Privacidad Total (Local): Se ejecuta localmente en tu navegador (
127.0.0.1:3333). Tus logs sensibles nunca salen de tu máquina ni suben a la nube. - Exploración por Facetas (Faceting): En lugar de «filtrar» (donde ocultas filas y pierdes contexto), OpenRefine usa «facetas». Esto te permite ver la distribución de todos los valores de una columna de un vistazo (ej. ver todas las IPs únicas y cuántas veces aparecen simultáneamente).
- Historial Infinito y Reproducible: Cada paso que das se guarda. Si cometes un error en el paso 50, puedes volver al paso 49 instantáneamente. Además, puedes exportar tu «receta» de limpieza (un JSON con los pasos) para aplicarla automáticamente a futuros logs similares. Esto es vital para la repetibilidad forense.
- Lenguaje GREL: Posee su propio lenguaje (General Refine Expression Language), similar a Python pero optimizado para transformaciones rápidas de texto y fechas.
| Característica | Excel | Scripts (Python/Bash) | OpenRefine |
| Volumen de datos | Limitado (se vuelve lento) | Ilimitado | Medio/Alto (hasta RAM disponible) |
| Curva de aprendizaje | Baja | Alta | Media |
| Visibilidad de errores | Baja (ocultos en celdas) | Baja (ciego hasta ejecutar) | Alta (Visualización inmediata) |
| Trazabilidad | Nula (Ctrl+Z limitado) | Alta (código) | Alta (Historial de pasos) |
🛠️ Tutorial Práctico: Limpieza de Logs Web
A continuación, veremos un caso de uso real simulado para investigar un incidente mediante logs web.
📌 Dataset utilizado: demo_logs_openrefine.csv (simulación de tráfico web con anomalías).
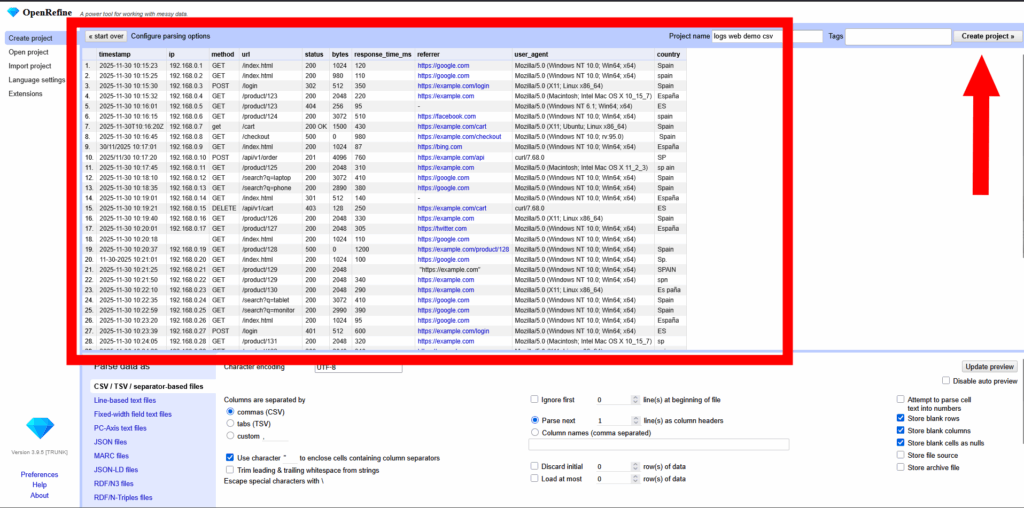
📥 1. Creación del proyecto
Pasos iniciales:
- Inicia OpenRefine y ve al navegador (
http://127.0.0.1:3333). - Menú izquierdo → Create Project.
- Pestaña This Computer → Browse → Selecciona
demo_logs_openrefine.csv. - Clic en Next ».
Configuración de importación crítica:
OpenRefine intentará adivinar el formato. Asegúrate de verificar:
- ✅ Character encoding: UTF-8 (vital para no romper caracteres especiales).
- ✅ Parse next 1 line(s) as column headers: Marcado.
- ❌ Store blank rows: Desmarcar si quieres eliminar ruido vacío desde el inicio.
Nombra el proyecto: Logs_Investigacion_Web y pulsa Create Project.
🔎 2. Exploración: El poder de las Facetas
Lo primero en una investigación no es limpiar, es entender. Las facetas nos permiten ver anomalías macroscópicas.
2.1 Faceta de Texto: method
¿Qué métodos HTTP se están usando?
- Ruta: Clic en columna
method→ Facet → Text facet.
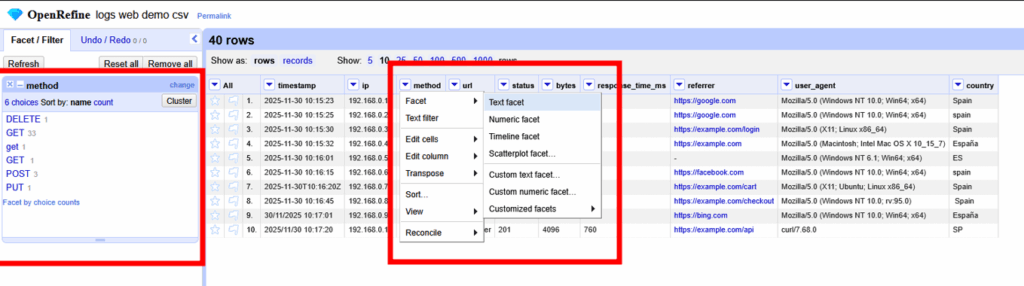
Hallazgo: Vemos inconsistencias como GET, get, Get. Esto indica que los logs vienen de fuentes distintas o han sido manipulados manualmente. Debemos normalizar esto.
2.2 Faceta Numérica: status
¿Hay muchos errores 404 o 500?
- Ruta: Columna
status→ Facet → Numeric facet.
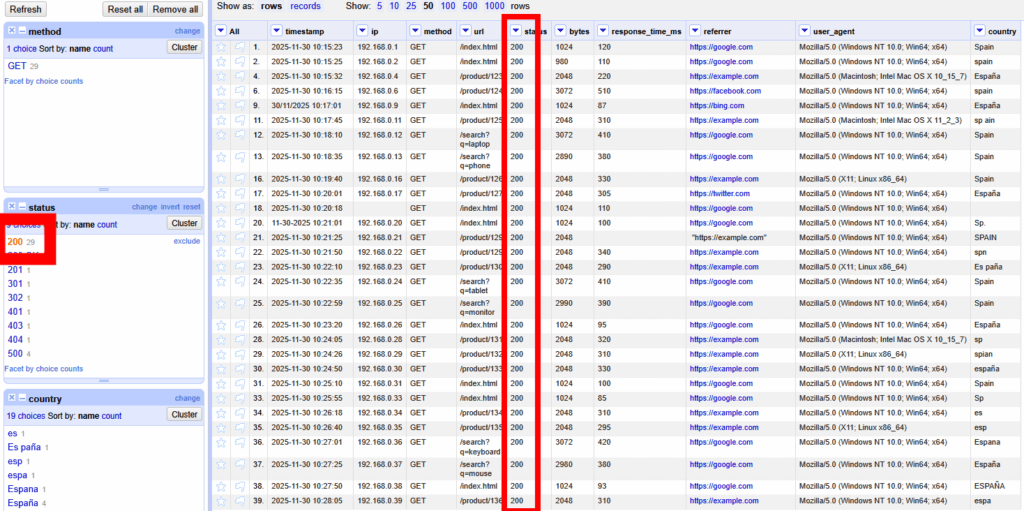
Esto genera un histograma. Podemos arrastrar los controles para filtrar solo los códigos de error (ej. mayores a 400) y ver qué IPs los generan.
2.3 Faceta de País: country
- Ruta: Columna
country→ Facet → Text facet.
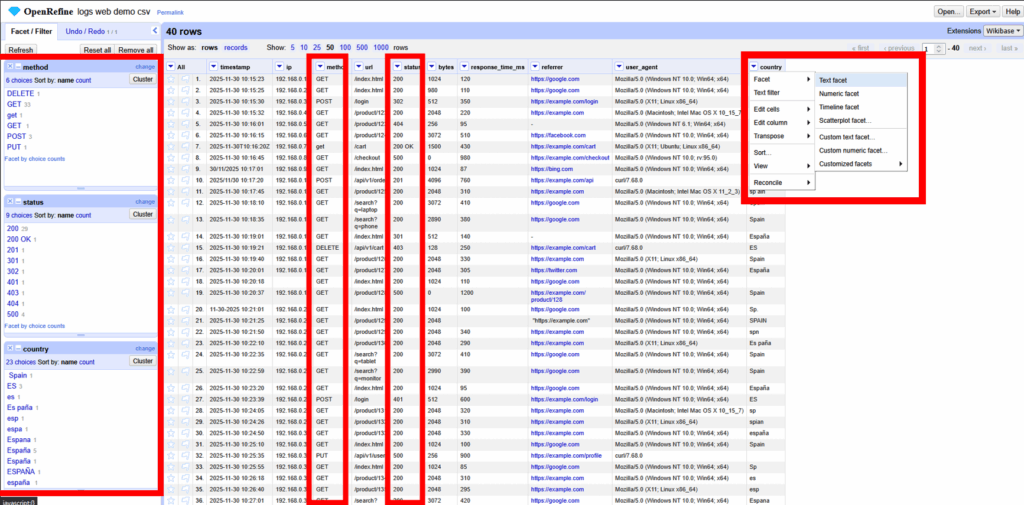
Hallazgo: Vemos valores sucios como espacios en blanco (» ES») o códigos desconocidos (??).
🧹 3. Limpieza y Normalización
3.1 Trim (Recortar espacios)
Los espacios en blanco al inicio o final de una cadena son enemigos silenciosos en los scripts de detección.
- Ruta:
Edit cells→Common transforms→ Trim leading and trailing whitespace. - Aplicar en:
path,user_agent,country.
Antes: " ES " ➡ Después: "ES"
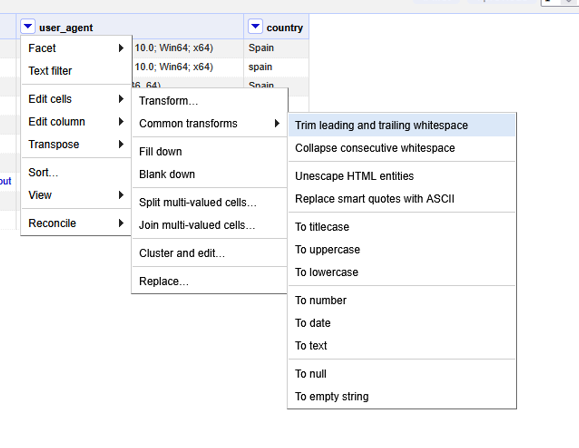
3.2 Normalizar Texto (Mayúsculas)
Unificamos los métodos HTTP.
- Ruta: Columna
method→Edit cells→Common transforms→ To upper case. - Resultado: Todos los
get,Getse convierten enGET.
♻️ 4. Eliminación de Duplicados
Los logs duplicados inflan las estadísticas y cansan la vista del analista.
- Ordenar: Columna
timestamp→ Sort. - Reordenar filas permanentemente: Menú
Sort(arriba) → Reorder rows permanently. - Detectar duplicados:
- Podemos crear una columna «hash» concatenando los valores clave o usar la función integrada de duplicados si tenemos un ID único.
- Método simple:
Edit cells→Blank down(si están ordenados idénticos) y luego borrar vacíos. - Método avanzado (GREL): Crear una columna huella digital.
🕓 5. Normalización de Timestamps (GREL)
Las fechas suelen ser el mayor dolor de cabeza. OpenRefine permite parsearlas inteligentemente.
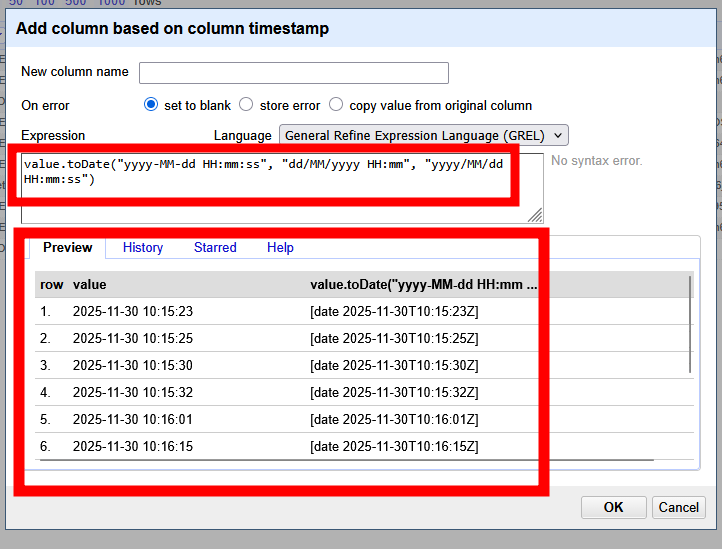
Ruta: Columna timestamp → Edit cells → Transform…
Usaremos GREL (General Refine Expression Language):
JavaScript
value.toDate()
O si el formato es muy complejo, podemos especificarlo:
JavaScript
value.toDate("yyyy-MM-dd HH:mm:ss")
Esto convierte el texto plano en un objeto fecha real, permitiendo luego extraer horas, días o calcular deltas de tiempo.
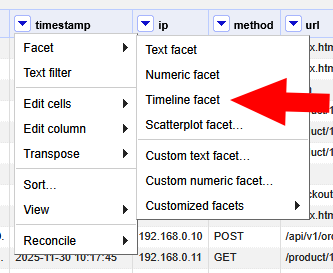
Ahora podemos usar Timeline Facet para ver la actividad a lo largo del tiempo:
🧠 6. Clustering: Magia para Logs de Texto Libre
El Clustering es la función estrella. Utiliza algoritmos (como fingerprint o nearest neighbor) para encontrar textos que son «casi» iguales pero difieren por una letra o un error tipográfico.
Caso de uso: Normalizar User Agents o Mensajes de error.
Ruta: Columna message → Edit cells → Cluster and edit…
OpenRefine agrupará:
User logged inUser loged in(typo)user logged in
Te permite seleccionar el valor correcto y aplicarlo a todas las variantes con un solo clic.
🚨 7. Enriquecimiento para el Análisis
Podemos crear nuevas columnas basadas en lógica para resaltar amenazas.
Ejemplo: Clasificar latencia (posible DoS o carga alta)
Ruta: Columna response_time → Edit column → Add column based on this column…
Nombre: risk_level
Expresión GREL:
JavaScript
if(value > 1500, "CRÍTICO",
if(value > 500, "ALTO", "NORMAL")
)
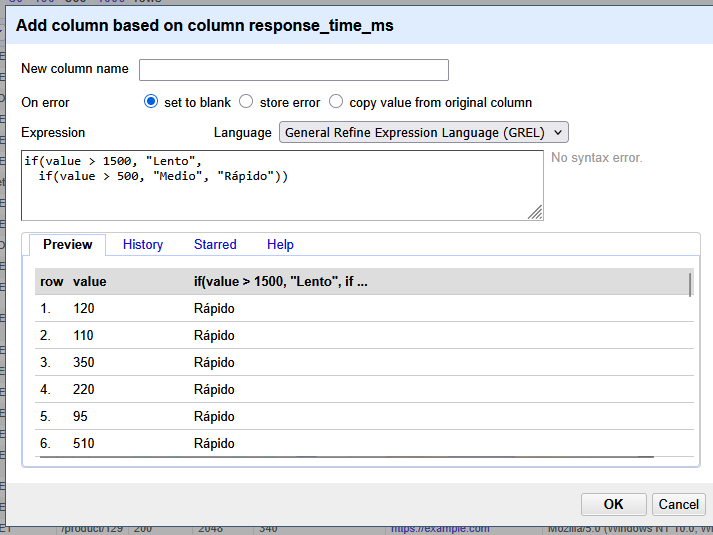
Ahora podemos filtrar por risk_level = CRÍTICO y ver qué IPs están causando los retrasos.
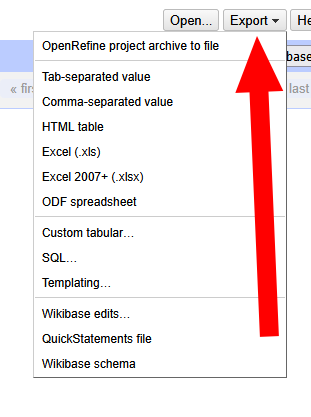
📤 8. Exportación
Una vez limpios, los datos están listos para ser ingeridos por un SIEM, Kibana, o añadidos a un informe forense.
- Botón Export (arriba derecha) → Comma-separated value (CSV) o Excel.
🧾 Conclusiones
OpenRefine no sustituye a un SIEM, pero es el paso intermedio esencial cuando los datos crudos son ilegibles.
- Limpia inconsistencias que los scripts automáticos pasan por alto.
- Normaliza formatos para que la ingestión en Elastic/Splunk no falle.
- Descubre patrones ocultos gracias a las facetas visuales.
Para un analista de DFIR, dominar OpenRefine es ganar horas de tiempo que antes se perdían peleando con hojas de cálculo.